
[1% 네트워크] chapter 1. 웹 브라우저가 메시지를 만든다.

이 글은 '성공과 실패를 결정하는 1%의 네트워크 원리'를 읽고 정리하는 글입니다.
웹 브라우저가 메시지를 웹 서버에 전송하기까지의 과정을 읽고 전체 글을 읽으면 좋을 것 같다.
- HTTP Request Message 작성
- 웹 서버의 IP 주소를 DNS 서버에서 조회
- 프로토콜 스택에 메시지 송신 의뢰
📕 1. HTTP Request Message 작성 📕
📑 1-1. 브라우저에서 URL 입력
브라우저
- : 여러 클라이언트 기능을 겸한 복합적인 클라이언트 소프트웨어
- ex: 웹 서버에 액세스하는 클라이언트, 파일 다운/업로드하는 FTP의 클라이언트, 메일의 클라이언트, ...
- 어떤 클라이언트를 사용하는지는 URL에서 알려줌
URL
- = Uniform Resource Locator
- http, ftp, mailto 다양한 스킴 존재
- 액세스 스킴을 통해 브라우저에서 어떤 클라이언트 기능을 사용할지 결정하게 됨
🔻 프로토콜 vs 스킴
프로토콜: 통신 동작의 규칙을 정한 것
액세스 스킴 부분을 '프로토콜'이라고 표현한 글들도 많이 보았을 것이다. http나 https 등을 사용하는 경우엔 네트워크를 사용해야 하므로 프로토콜이라고 불린다. 하지만 URL은 file 같이 네트워크를 사용하지 않고도 액세스하는 경우가 존재하므로 스킴 = 프로토콜이라고 단언할 수 없다. 스킴 ⊃ 프로토콜로 이해하자.
📑 1-2. 브라우저가 URL 해석
http://www.yeonyeon.tistory.com:8080/dir/test.html
- http: 액세스 방법. http 프로토콜 이용
- www.yeonyeon.tistory.com:8080: 웹서버 명
- /dir/test.html: 데이터 출처 경로명 (경로가 생략되는 경우 서버 측에서 미리 설정해둔 index.html 같은 파일 사용)
🔻 경로 /test와 /test/는 뭐가 다를까?
- http://www.yeonyeon.tistory.com/test
- http://www.yeonyeon.tistory.com/test/
1: test는 파일명
2: test는 디렉토리명
📑 1-3. HTTP Request Message 생성
- client가 server에게 보내는 메시지
- '무엇'을 '어떻게' 할지에 대한 정보가 담김
- 메서드
- '어떻게'
- 웹 서버에 어떤 동작을 하고 싶은지
- ex: GET, POST, ...
- URI
- '무엇을'
- 데이터를 저장한 파일명, CGI 프로그램의 파일명, ...
- 메시지 헤더
- request에 대한 부가 정보
- ex: 데이터 종류, 데이터 언어, 소프트웨어 버전, ...
- 메시지 본문
- client가 server에 보낼 데이터
CGI: 웹 서버 소프트웨어에서 프로그램을 호출할 때의 규칙을 정한 것
CGI 프로그램: GGI 규칙에 맞게 움직이는 프로그램
📑 1-4. HTTP Response Message 수신
- server가 client에게 보내는 메시지
- 스테이터스 코드
- 실행 결과를 알려주기 위한 코드
- ex: 400, 401, 404, ...
- 메시지 헤더
- response에 대한 부가 정보
- ex: 데이터 종류, 데이터 언어, 소프트웨어 버전, ...
- 메시지 본문
- server가 client에 보낼 데이터
📑 1-5. 정리
- 브라우저에서 URL 입력
- 브라우저가 URL 해석
- HTTP Request Message 생성 및 전송
- HTTP Response Message 수신
아래 글에서는 3의 전송 과정에서 어떤 과정에 대해 세세하게 다뤄보겠다.
📒 2. 웹서버의 IP 주소를 DNS 서버에서 조회 📒
1에서 살펴봤듯이 브라우저는 URL을 해석하고 HTTP 메시지를 생성하는 기능을 가졌다. 하지만 HTTP 메시지를 송출하는 기능은 없어서 OS에게 송신 의뢰를 하게 된다. OS에게 송신 의뢰를 할 때는 도메인 명이 아닌 IP 주소로 수신 상대를 지정 가능하다.
도메인명을 IP 주소로 변환하는 과정 자체에 의문을 가질 수 있다. 그냥 하나만 쓰면 안되나? 왜 변환 과정이 필요하지? 대표적인 의문 몇 가지를 정리하고 이 방법이 왜 안되는지 생각해보자.
- 애초에 클라이언트가 IP 주소를 입력하게 하면 안될까?
- 👉 사용자가 IP 주소를 하나하나 기억하기가 어렵다.
- 👉 사용자가 IP 주소를 하나하나 기억하기가 어렵다.
- 도메인명으로도 통신 가능하게 만든다면?
- 👉 실행 효율 ↓, 라우터에 부하
- IP 주소: 32 bit = 4 byte
도메인명: 수십 ~ 255 byte - 고성능 라우터를 사용한다면? 그래도 라우터의 속도에는 한계가 있다. 라우터 속도의 발전이 꾸준히 이루어지고 있는만큼 통신할 데이터의 양도 증가하고 있다.
이제 도메인명과 IP 주소를 왜 따로 구분지어 사용하는지 충분히 납득 되었기를 바란다. 본격적으로 IP 주소를 찾아내는 과정을 설명하기 전에 아래 용어들도 살펴보자.
🔻 TCP/IP란?
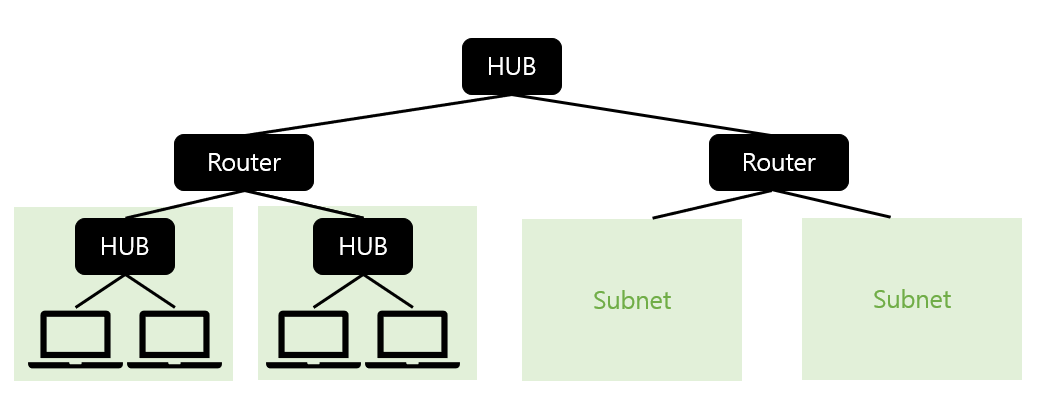
- 서브넷이라는 작은 네트워크를 라우터로 접속하는 형태로 전체 네트워크가 구성됨
- 서브넷에 IP 주소 할당
- 이를 통해 액세스 대상의 위치 판별 가능하게 됨
- IP 주소 = 네트워크 번호 + 호스트 번호
- 서브넷에는 네트워크 번호, PC에는 호스트 번호가 붙는 식으로 할당됨
- 메시지 전송 과정
- 송신 측에서 가장 가까운 라우터까지 운반 (운반은 허브가 해준다)
- 라우터가 메시지 보낸 상대 확인 + 다음 라우터 판단
- 다음 라우터로 운반하여 2 반복
- 2~3 반복하다 최종적으로 상대의 데이터 도착
서브넷이란?
- : 작은 네트워크.
- 허브 한 대에 PC 여러 대가 접속된 형태
- PC가 적으면 허브 1대로 충분
하지만 수가 많아지면 허브들을 연결해 허브의 수를 늘림
이 때 허브들을 연결한 것도 서브넷으로 취급.
🔻 넷마스크란?
IP 주소는 네트워크 번호와 호스트 번호로 이루어져있다. 32 bit로 제한한다. 라고 정해져있다. 하지만 이 정보들 뿐만으로는 IP 주소를 딱 봤을 때 어디가 네트워크고 어디가 호스트인지 구분할 수 없다. 이를 구분할 수 있게 도와주는 정보를 넷마스크라고 하는데 네트워크 구축 시 결정된다.

서브넷 마스크
- '1' 비트: 네트워크 번호
- '0' 비트: 호스트 번호
IP 주소의 호스트 번호
- 모두 '0': 서브넷 그 자체
- 모두 '1': 브로드캐스트 (서브넷에 있는 기기 전체에 패킷 전송)
넷마스크에 따라 IP 주소의 클래스가 나뉘기도 한다.
- 클래스 A
- 서브넷 마스크: 255.0.0.0
- IP 주소의 첫 옥텟: 0 ~ 127로 구성
- 클래스 B
- 서브넷 마스크: 255.255.0.0
- IP 주소의 첫 옥텟: 128 ~ 191
- 중간 규모와 대규모 네트워크에서 이용
- 클래스 C
- 서브넷 마스크: 255.255.255.0
- IP 주소의 첫 옥텟: 192 ~ 223
- LAN(Local Area Network)에서 이용
클래스 A~C는 옥텟(8개 비트) 단위로 나뉘었지만 1개의 비트 단위로 구분하기도 한다.
ex: 11111111.11111111.11111100.00000000
📑 2-1. 리졸버를 이용해 DNS 서버 조회하기
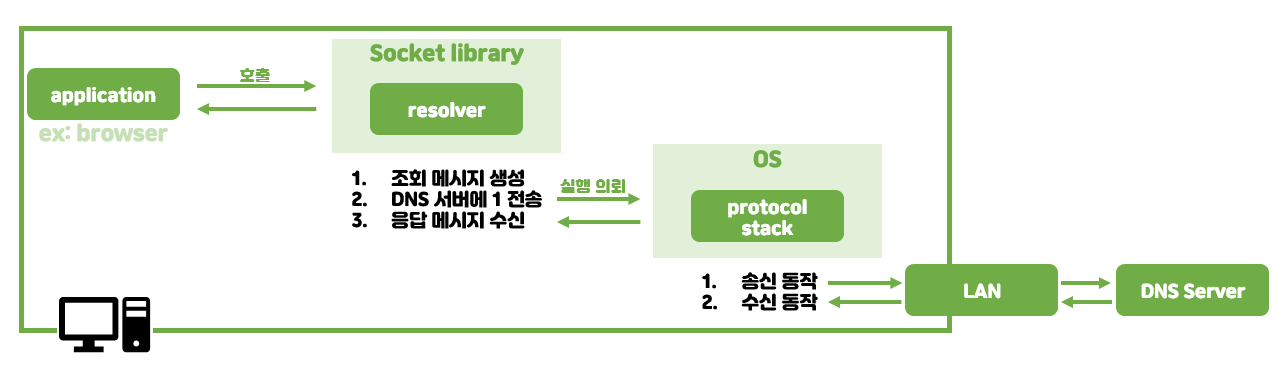
1. 애플리케이션(ex: 브라우저)에서 리졸버 호출
- 리졸버: Socket 라이브러리의 부품 중 하나. 네임 리졸루션을 실행.
- Socket 라이브러리: OS에 포함된 네트워크 기능을 애플리케이션에서 호출하기 위한 부품을 모아둔 것.
- 네임 리졸루션: DNS 원리를 사용해 IP 주소를 조사
- ex: <메모리 영역> = getHostByName("www.yeonyeon.tistory.com");
저장할 메모리의 위치 = 리졸버 프로그램명(도메인명);
2. 리졸버가 DNS 서버에 메시지 전송 & 수신
- 조회 메시지 생성
- 이름: 목적지 이름
- 클래스: 여러 네트워크를 식별하기 위한 정보
(이제는 인터넷 외의 네트워크가 사라지게 되어 'IN'으로 고정되었다.) - 타입: 이름에 어떤 타입 정보가 지원되는지
(ex: A => Address의 약자. IP 주소)
- 생성한 메시지 DNS 서버에 전송
- 리졸버 자체에서 DNS 서버에 송신하는 기능 X
👉 OS 내부의 프로토콜 스택에 실행 의뢰 - 프로토콜 스택
: OS에 내장된 네트워크 제어용 소프트웨어.
여기서는 DNS 서버로 송수신 동작을 위해 사용.
(자세한 것은 이 글의 마지막 파트인 3. 프로토콜 스택에 메시지 송신 의뢰에서 다룬다.) - DNS 서버를 찾는 과정은 2-2 참고
- 리졸버 자체에서 DNS 서버에 송신하는 기능 X
- DNS 서버로부터 응답 메시지 수신
3. 2에서 수신 받은 데이터를 메모리 영역에 저장
이렇게 받아온 응답 메시지에서 IP 주소를 추출해낼 수 있다. 이후에 웹서버에 요청을 보낼 때 추출해서 메모리에 저장해두었던 IP 주소를 HTTP request message와 함께 OS에 송신 의뢰를 보내게 된다.
📑 2-2. DNS 서버 조회 과정
DNS 서버는 어떻게 찾는걸까? DNS 서버의 IP 주소를 알아야 접근 가능하지 않을까? 이 부분에 대해 알기 위해서는 먼저 DNS 서버의 구조에 대해 알아야 한다.
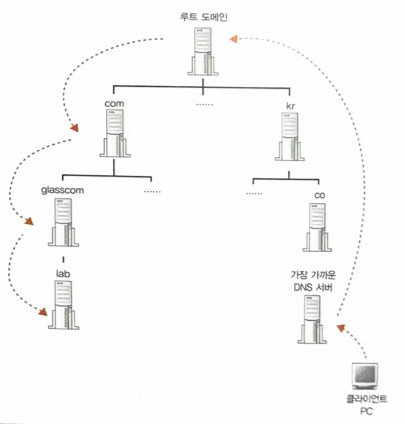
DNS 서버는 위와 같은 구조로 구성되어 있다.
참고로 루트 도메인의 DNS 서버는 TCP/IP 설정에 저장되어있다.
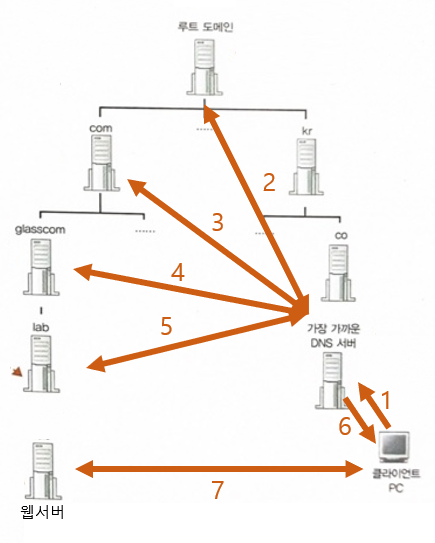
1. 가장 가까운 DNS 서버
- 가까운 DNS 서버에 조회 메시지 전송
- 가까운 DNS 서버의 리소스 레코드에서 필요한 정보가 있는지 찾기
2. (1에 필요한 정보가 없었다면) TCP/IP 설정에 저장된 DNS 서버 조회
- = 루트 도메인 DNS 서버
- 루트 도메인 DNS 서버에 조회 메시지 전송
- 루트 도메인 DNS 서버의 리소스 레코드에서 필요한 정보가 있는지 찾기
3. (2에 필요한 정보가 없었다면) 하위 도메인 DNS 서버에서 찾으라는 응답 수신
- 하위 도메인 DNS 서버에 조회 메시지 전송
- 하위 도메인 DNS 서버의 리소스 레코드에서 필요한 정보가 있는지 찾기
4. 올바른 IP 주소를 찾지 못해 3 반복
5. 올바른 IP 주소를 찾아 IP 주소를 포함한 응답 수신
6. IP 주소를 클라이언트에 응답
7. 웹 서버의 IP 주소에 액세스
🔻 DNS 서버와 캐시
DNS 서버는 한 번 조사한 이름을 캐시에 기록할 수 있다. 조회한 이름이 도메인이 등록되어 있으면 위와 같은 과정을 거치지 않을 수 있다. 다만 캐시에 정보를 저장한 후 등록 정보가 변경되는 경우가 있으므로 항상 올바른 정보라고 단언할 수 없다. 따라서 DNS 서버에 등록하는 정보는 유효 기한을 설정하고 캐시에 저장한 데이터 유효 기간이 지나면 삭제된다. 또한 조회 시 캐시에서 가져왔는지, DNS 서버에서 가져왔는지 알려준다.
📗 3. 프로토콜 스택에 메시지 송신 의뢰 📗
📑 3-1. 프로토콜 스택
- OS 내부에 존재
- 액세스 대상의 웹 서버에 메시지를 송신하는 역할
- 브라우저뿐 아니라 모든 네트워크 애플리케이션에서도 사용
📑 3-2. 데이터 송수신 동작 과정
동작을 실행시키는 주체: OS 내부의 프로토콜 스택
동작이 실행되는 주체: Socket 라이브러리 내부의 프로그램 부품
소켓
: 데이터 송수신 동작을 위해서는 서버와 클라이언트 사이를 파이프로 연결해야 한다. 소켓은 이 파이프의 양 끝의 데이터 출입구를 의미한다. 소켓에는 연결된 상대가 기록되어 있어 디스크립터로 소켓을 지정하면 연결된 상대 판명 가능하다.
Socket 라이브러리의 호출 순서
<메모리 영역> = gethostbyname("url");
<디스크립터> = socket(<IPv4사용>, <스트림형>, ...); // 소켓 생성
connect(<디스크립터>, <서버IP주소+포트번호>, ...); // 파이프 연결
write(<디스크립터>, <송신 데이터>, <송신 데이터 길이>); // 데이터 송신
<수신 데이터 길이> = read(<디스크립터>, <수신 버퍼>, ...); // 데이터 수신
close(<디스크립터>); // 파이프 끊기
1. 소켓 생성
2. 서버측의 소켓에 파이프 연결
- Socket 라이브러리의 connect 호출
- 연결 시 디스크립터, 서버 IP 주소, 서버 포트 번호 필요
- 디스크립터: 애플리케이션이 소켓을 식별하기 위해 사용
- 서버 IP 주소 + 포트 번호: 클라이언트 - 서버 간에 상대의 소켓을 식별하는 것
3. 데이터 송신
- 애플리케이션은 송신 데이터를 메모리에 준비
- Socket 라이브러리의 write 호출해 프로토콜 스택에 송신 동작 의뢰
- 프로토콜이 서버에게 데이터 송신
- 네트워크를 통해 서버에 데이터 도착
- 서버가 수신한 데이터의 내용을 조사하고 적절한 처리
- 서버가 응답 메시지 반송
4. 데이터 수신
- Socket 라이브러리의 read를 통해 프로토콜 스택에 수신 동작 의뢰
- 이때 응답 메시지를 저장하기 위한 메모리 영역 지정
- 이 메모리 영역을 수신 버퍼라고 부름
- 응답 메시지가 도착하면 수신 버퍼에 저장
- 수신 버퍼: 애플리케이션 프로그램 내부에 마련된 메모리 영역
- 수신 버퍼에 메시지를 저장 후 애플리케이션에 건냄
5. 연결 끊기
- Socket 라이브러리의 close 호출
- 소켓 사이에 연결된 파이프 분리 + 소켓 말소
- 클라이언트 측에 전달됨
- 소켓 연결 끊기
close는 주로 서버가 먼저 하지만 클라이언트에서 먼저 하는 경우도 있다. 어느 쪽에서 close 해도 연결은 무사히 끊긴다.
📑 3-3. connect를 호출할 때 필요한 것
디스크립터
- 최초의 디스크립터: 소켓 생성 시 반환된 디스크립터
- 해당 디스크립터를 connect가 프로토콜 스택에 통지
- 프로토콜 스택은 통지받은 디스크립터로 소켓 식별해 접속 동작 실행
- 컴퓨터 한 대의 내부에서 소켓을 식별하기 위해 사용
서버의 IP 주소
- DNS 서버에 조회해 조사한 액세스 대상 서버의 IP 주소
- 송수신하는 상대의 IP 주소
- 네트워크의 어느 컴퓨터에 접근해야하는가 판별 가능 (소켓까지는 판별 X)
서버의 포트 번호
- 소켓 판별 가능하게 도와줌
- 접속을 시도하는 측(클라이언트)에서 (서버측) 소켓을 식별하기 위한 중간 과정에 사용
포트 번호
URL에서 포트 번호가 생략되는 경우가 많다. 세계적으로 통일된 포트 번호 규칙이 있기 때문이다. (ex: 80번은 웹, 25번은 메일, ...) IP 주소같이 다른 것과 중복되지 않도록 IANA라는 기관이 관리한다.
서버는 클라이언트의 포트 번호를 어떻게 아는가?
- 클라이언트 쪽 소켓의 포트 번호: 소켓 생성 시 프로토콜 스택이 적당한 값을 골라서 할당
- 접속 동작을 실행할 때 1을 서버에 통지
참고
- 성공과 실패를 결정하는 1%의 네트워크 원리 - Chapter 01
- https://nordvpn.com/ko/blog/what-is-subnet-mask/